| Lesson 2 | HTTP review |
| Objective | Roles of the Client (browser) and Server on the Web |
Roles of Client and Server on the Web
Describe the roles of the client (browser) and server on the Web.
Whenever a user types a URL into the browser, follows a link, or selects a bookmarked or favorite site, the browser will retrieve that URL. Links, bookmarks, and favorites all contain a URL for the browser to use. If the URL starts with “http://”, the browser requests the file from a Web server. To do this, it pulls apart the URL, extracting the host name, and perhaps the port, and the requested file and path.
For example:
Whenever a user types a URL into the browser, follows a link, or selects a bookmarked or favorite site, the browser will retrieve that URL. Links, bookmarks, and favorites all contain a URL for the browser to use. If the URL starts with “http://”, the browser requests the file from a Web server. To do this, it pulls apart the URL, extracting the host name, and perhaps the port, and the requested file and path.
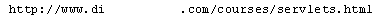
Dissecting URL
After determining the host name, the browser makes an Internet connection to the Web server, and sends it a request for the file.
If it was retrieving our example URL, it would connect to www.javadeploy.com and say:
This request starts with GET because the browser wants the server to get the file.
Then come
If it was retrieving our example URL, it would connect to www.javadeploy.com and say:
GET /courses/servlets.html HTTP/1.0
This request starts with GET because the browser wants the server to get the file.
- the path,
- file name, and
- finally the level of the
This HTTP level does not matter to us. After the GET request, a browser will usually send other information about itself to the server.
This other information is often referred to as the request headers.
The server sends a short response code, usually “200 OK” but occasionally the famous
(lines of information about the server), and, if there is a file to return, the full contents of the requested file. This is HTML, and the browser will render it on the screen for the user.
In the next lesson, the “stateless” characteristics of the HTTP protocol will be discussed.
This other information is often referred to as the request headers.
The server sends a short response code, usually “200 OK” but occasionally the famous
“404 Not Found,” some “response headers”
(lines of information about the server), and, if there is a file to return, the full contents of the requested file. This is HTML, and the browser will render it on the screen for the user.
In the next lesson, the “stateless” characteristics of the HTTP protocol will be discussed.
[1] HTTP Protocol:The rules that cover how a browser asks for a resource from a server, and how a server tells the browser that resource is available or not.